
Information is at the core of human progress.
It’s why we’ve focused for more than 26 years on our mission to organize the world’s information and make it accessible and useful. And it’s why we continue to push the frontiers of AI to organize that information across every input and make it accessible via any output, so that it can be truly useful for you.
That was our vision when we introduced Gemini 1.0 last December. The first model built to be natively multimodal, Gemini 1.0 and 1.5 drove big advances with multimodality and long context to understand information across text, video, images, audio and code, and process a lot more of it.
Now millions of developers are building with Gemini. And it’s helping us reimagine all of our products — including all 7 of them with 2 billion users — and to create new ones. NotebookLM is a great example of what multimodality and long context can enable for people, and why it’s loved by so many.
Over the last year, we have been investing in developing more agentic models, meaning they can understand more about the world around you, think multiple steps ahead, and take action on your behalf, with your supervision.
Today we’re excited to launch our next era of models built for this new agentic era: introducing Gemini 2.0, our most capable model yet. With new advances in multimodality — like native image and audio output — and native tool use, it will enable us to build new AI agents that bring us closer to our vision of a universal assistant.
We’re getting 2.0 into the hands of developers and trusted testers today. And we’re working quickly to get it into our products, leading with Gemini and Search. Starting today our Gemini 2.0 Flash experimental model will be available to all Gemini users. We’re also launching a new feature called Deep Research, which uses advanced reasoning and long context capabilities to act as a research assistant, exploring complex topics and compiling reports on your behalf. It’s available in Gemini Advanced today.
No product has been transformed more by AI than Search. Our AI Overviews now reach 1 billion people, enabling them to ask entirely new types of questions — quickly becoming one of our most popular Search features ever. As a next step, we’re bringing the advanced reasoning capabilities of Gemini 2.0 to AI Overviews to tackle more complex topics and multi-step questions, including advanced math equations, multimodal queries and coding. We started limited testing this week and will be rolling it out more broadly early next year. And we’ll continue to bring AI Overviews to more countries and languages over the next year.
2.0’s advances are underpinned by decade-long investments in our differentiated full-stack approach to AI innovation. It’s built on custom hardware like Trillium, our sixth-generation TPUs. TPUs powered 100% of Gemini 2.0 training and inference, and today Trillium is generally available to customers so they can build with it too.
If Gemini 1.0 was about organizing and understanding information, Gemini 2.0 is about making it much more useful. I can’t wait to see what this next era brings.
-Sundar
Introducing Gemini 2.0: our new AI model for the agentic era
By Demis Hassabis, CEO of Google DeepMind and Koray Kavukcuoglu, CTO of Google DeepMind on behalf of the Gemini team
Over the past year, we have continued to make incredible progress in artificial intelligence. Today, we are releasing the first model in the Gemini 2.0 family of models: an experimental version of Gemini 2.0 Flash. It’s our workhorse model with low latency and enhanced performance at the cutting edge of our technology, at scale.
We are also sharing the frontiers of our agentic research by showcasing prototypes enabled by Gemini 2.0’s native multimodal capabilities.
Gemini 2.0 Flash
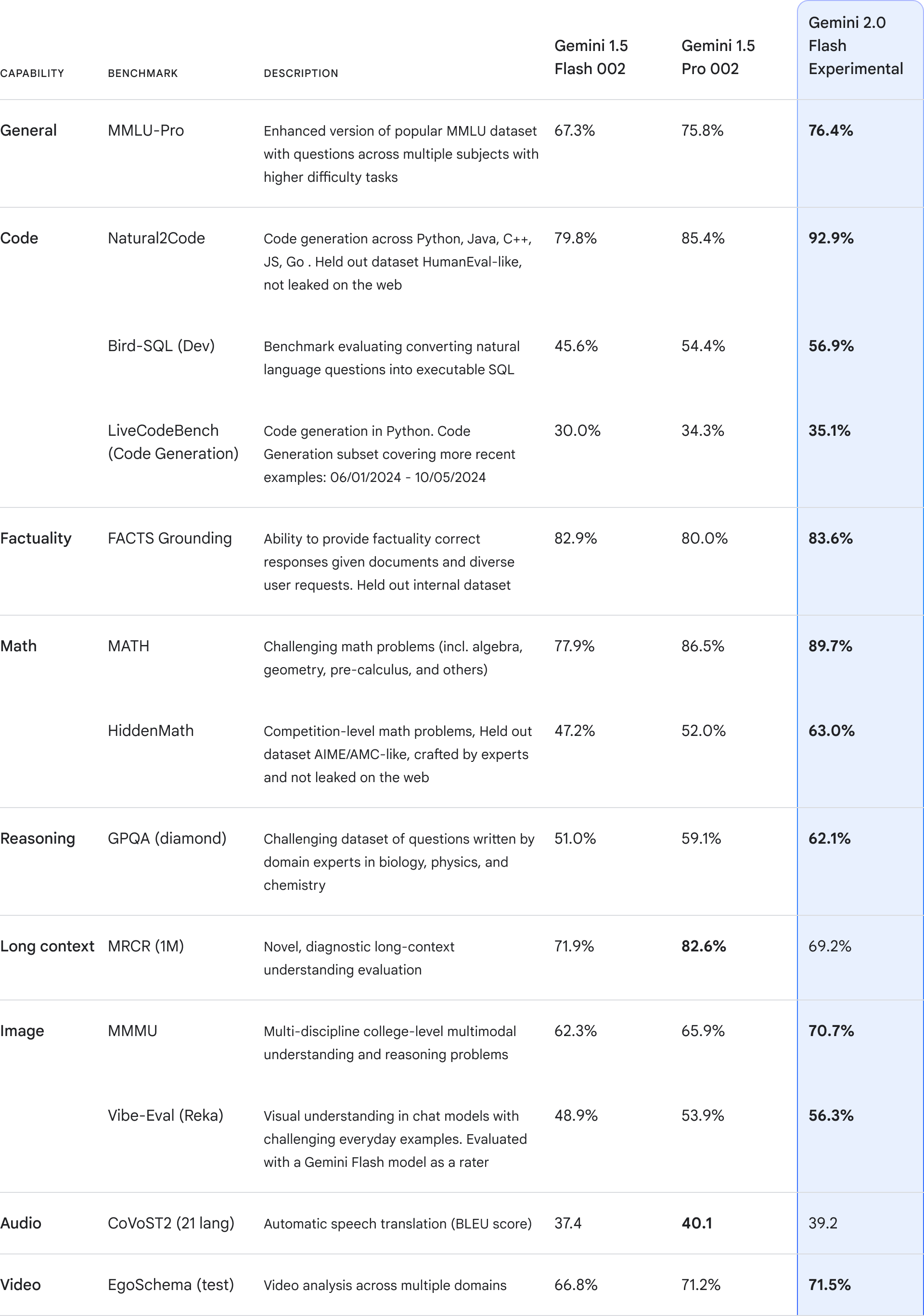
Gemini 2.0 Flash builds on the success of 1.5 Flash, our most popular model yet for developers, with enhanced performance at similarly fast response times. Notably, 2.0 Flash even outperforms 1.5 Pro on key benchmarks, at twice the speed. 2.0 Flash also comes with new capabilities. In addition to supporting multimodal inputs like images, video and audio, 2.0 Flash now supports multimodal output like natively generated images mixed with text and steerable text-to-speech (TTS) multilingual audio. It can also natively call tools like Google Search, code execution as well as third-party user-defined functions.
Our goal is to get our models into people’s hands safely and quickly. Over the past month, we’ve been sharing early, experimental versions of Gemini 2.0, getting great feedback from developers.
Gemini 2.0 Flash is available now as an experimental model to developers via the Gemini API in Google AI Studio and Vertex AI with multimodal input and text output available to all developers, and text-to-speech and native image generation available to early-access partners. General availability will follow in January, along with more model sizes.
To help developers build dynamic and interactive applications, we’re also releasing a new Multimodal Live API that has real-time audio, video-streaming input and the ability to use multiple, combined tools. More information about 2.0 Flash and the Multimodal Live API can be found in our developer blog.
Gemini 2.0 available in Gemini app, our AI assistant
Also starting today, Gemini users globally can access a chat optimized version of 2.0 Flash experimental by selecting it in the model drop-down on desktop and mobile web and it will be available in the Gemini mobile app soon. With this new model, users can experience an even more helpful Gemini assistant.
Early next year, we’ll expand Gemini 2.0 to more Google products.
Unlocking agentic experiences with Gemini 2.0
Gemini 2.0 Flash’s native user interface action-capabilities, along with other improvements like multimodal reasoning, long context understanding, complex instruction following and planning, compositional function-calling, native tool use and improved latency, all work in concert to enable a new class of agentic experiences.
The practical application of AI agents is a research area full of exciting possibilities. We’re exploring this new frontier with a series of prototypes that can help people accomplish tasks and get things done. These include an update to Project Astra, our research prototype exploring future capabilities of a universal AI assistant; the new Project Mariner, which explores the future of human-agent interaction, starting with your browser; and Jules, an AI-powered code agent that can help developers.
We’re still in the early stages of development, but we’re excited to see how trusted testers use these new capabilities and what lessons we can learn, so we can make them more widely available in products in the future.

Project Astra: agents using multimodal understanding in the real world
Since we introduced Project Astra at I/O, we’ve been learning from trusted testers using it on Android phones. Their valuable feedback has helped us better understand how a universal AI assistant could work in practice, including implications for safety and ethics. Improvements in the latest version built with Gemini 2.0 include:
- Better dialogue: Project Astra now has the ability to converse in multiple languages and in mixed languages, with a better understanding of accents and uncommon words.
- New tool use: With Gemini 2.0, Project Astra can use Google Search, Lens and Maps, making it more useful as an assistant in your everyday life.
- Better memory: We’ve improved Project Astra’s ability to remember things while keeping you in control. It now has up to 10 minutes of in-session memory and can remember more conversations you had with it in the past, so it is better personalized to you.
- Improved latency: With new streaming capabilities and native audio understanding, the agent can understand language at about the latency of human conversation.
We’re working to bring these types of capabilities to Google products like Gemini app, our AI assistant, and to other form factors like glasses. And we’re starting to expand our trusted tester program to more people, including a small group that will soon begin testing Project Astra on prototype glasses.

Project Mariner: agents that can help you accomplish complex tasks
Project Mariner is an early research prototype built with Gemini 2.0 that explores the future of human-agent interaction, starting with your browser. As a research prototype, it’s able to understand and reason across information in your browser screen, including pixels and web elements like text, code, images and forms, and then uses that information via an experimental Chrome extension to complete tasks for you.
When evaluated against the WebVoyager benchmark, which tests agent performance on end-to-end real world web tasks, Project Mariner achieved a state-of-the-art result of 83.5% working as a single agent setup.
It’s still early, but Project Mariner shows that it’s becoming technically possible to navigate within a browser, even though it’s not always accurate and slow to complete tasks today, which will improve rapidly over time.
To build this safely and responsibly, we’re conducting active research on new types of risks and mitigations, while keeping humans in the loop. For example, Project Mariner can only type, scroll or click in the active tab on your browser and it asks users for final confirmation before taking certain sensitive actions, like purchasing something.
Trusted testers are starting to test Project Mariner using an experimental Chrome extension now, and we’re beginning conversations with the web ecosystem in parallel.

Jules: agents for developers
Next, we’re exploring how AI agents can assist developers with Jules — an experimental AI-powered code agent that integrates directly into a GitHub workflow. It can tackle an issue, develop a plan and execute it, all under a developer’s direction and supervision. This effort is part of our long-term goal of building AI agents that are helpful in all domains, including coding.
More information about this ongoing experiment can be found in our developer blog post.
Agents in games and other domains
Google DeepMind has a long history of using games to help AI models become better at following rules, planning and logic. Just last week, for example, we introduced Genie 2, our AI model that can create an endless variety of playable 3D worlds — all from a single image. Building on this tradition, we’ve built agents using Gemini 2.0 that can help you navigate the virtual world of video games. It can reason about the game based solely on the action on the screen, and offer up suggestions for what to do next in real time conversation.
We’re collaborating with leading game developers like Supercell to explore how these agents work, testing their ability to interpret rules and challenges across a diverse range of games, from strategy titles like “Clash of Clans” to farming simulators like “Hay Day.”
Beyond acting as virtual gaming companions, these agents can even tap into Google Search to connect you with the wealth of gaming knowledge on the web.

In addition to exploring agentic capabilities in the virtual world, we’re experimenting with agents that can help in the physical world by applying Gemini 2.0’s spatial reasoning capabilities to robotics. While it’s still early, we’re excited about the potential of agents that can assist in the physical environment.
You can learn more about these research prototypes and experiments at labs.google.
Building responsibly in the agentic era
Gemini 2.0 Flash and our research prototypes allow us to test and iterate on new capabilities at the forefront of AI research that will eventually make Google products more helpful.
As we develop these new technologies, we recognize the responsibility it entails, and the many questions AI agents open up for safety and security. That is why we are taking an exploratory and gradual approach to development, conducting research on multiple prototypes, iteratively implementing safety training, working with trusted testers and external experts and performing extensive risk assessments and safety and assurance evaluations.
For example:
- As part of our safety process, we’ve worked with our Responsibility and Safety Committee (RSC), our longstanding internal review group, to identify and understand potential risks.
- Gemini 2.0’s reasoning capabilities have enabled major advancements in our AI-assisted red teaming approach, including the ability to go beyond simply detecting risks to now automatically generating evaluations and training data to mitigate them. This means we can more efficiently optimize the model for safety at scale.
- As Gemini 2.0’s multimodality increases the complexity of potential outputs, we’ll continue to evaluate and train the model across image and audio input and output to help improve safety.
- With Project Astra, we’re exploring potential mitigations against users unintentionally sharing sensitive information with the agent, and we’ve already built in privacy controls that make it easy for users to delete sessions. We’re also continuing to research ways to ensure AI agents act as reliable sources of information and don’t take unintended actions on your behalf.
- With Project Mariner, we’re working to ensure the model learns to prioritize user instructions over 3rd party attempts at prompt injection, so it can identify potentially malicious instructions from external sources and prevent misuse. This prevents users from being exposed to fraud and phishing attempts through things like malicious instructions hidden in emails, documents or websites.
We firmly believe that the only way to build AI is to be responsible from the start and we’ll continue to prioritize making safety and responsibility a key element of our model development process as we advance our models and agents.
Gemini 2.0, AI agents and beyond
Today’s releases mark a new chapter for our Gemini model. With the release of Gemini 2.0 Flash, and the series of research prototypes exploring agentic possibilities, we have reached an exciting milestone in the Gemini era. And we’re looking forward to continuing to safely explore all the new possibilities within reach as we build towards AGI.

